


Leon Yin is an investigative data journalist recognised for his work on how technology impacts society. He worked on the investigation that uncovered how Google doesn’t allow advertisers to use racial justice terms like Black Lives Matter while allowing the term White Lives Matter. Another investigation found that Facebook hasn’t been transparent about the popularity of right-wing content on its platform. And he worked on a project which uncovered that Google search prioritizes its own products in the top search results over other products. This work was mentioned in the antitrust hearings in July 2020 held by a US congressional subcommittee.
{kind=link}
When we interviewed Leon in April 2023 at the International Journalism Festival, he was working at The Markup, a non-profit newsroom focused on being the watchdog of the tech industry. He has since joined Bloomberg Technology, where he’s continuing his investigative work.
In addition to his articles, Leon publishes resources that explain how he worked on his investigations. Among the resources is Inspect Element, a guide he put together on how to conduct investigations into algorithms, build datasets and more.
We were excited to talk to Leon about his journey to becoming a data journalist. Here’s the interview, which you can listen to here, or watch here:
In Old News: Are you usually working on several projects at once? How do you balance that with learning new skills?
Leon: I say that I tend to like to work on two stories at once that are long term or like if something slows down, I can move to something else, either another long-term something or something a quicker churn, just to keep moving. Because it's easy to stagnate sometimes because I think that a lot of times with these investigations you really just need time and you need review from others and feedback.
It's really important to have a great relationship with your editor so that they understand what you're going through, but also helping you prioritize what's important. Right? Because there are infinite questions you could ask during these investigations. So it's like how to best use your time.
In Old News: One of your stories was mentioned during a congressional hearing. Could you walk us through how that happened, and is that an outcome you were expecting?
Leon: So the way that started was my reporting partner, Adrianne Jeffries, she's been reporting on Google for ages and she had done a lot on the featured snippet, which is kind of like the text box that's been scraped from the web and summarizes something, she's really fascinated about [that].
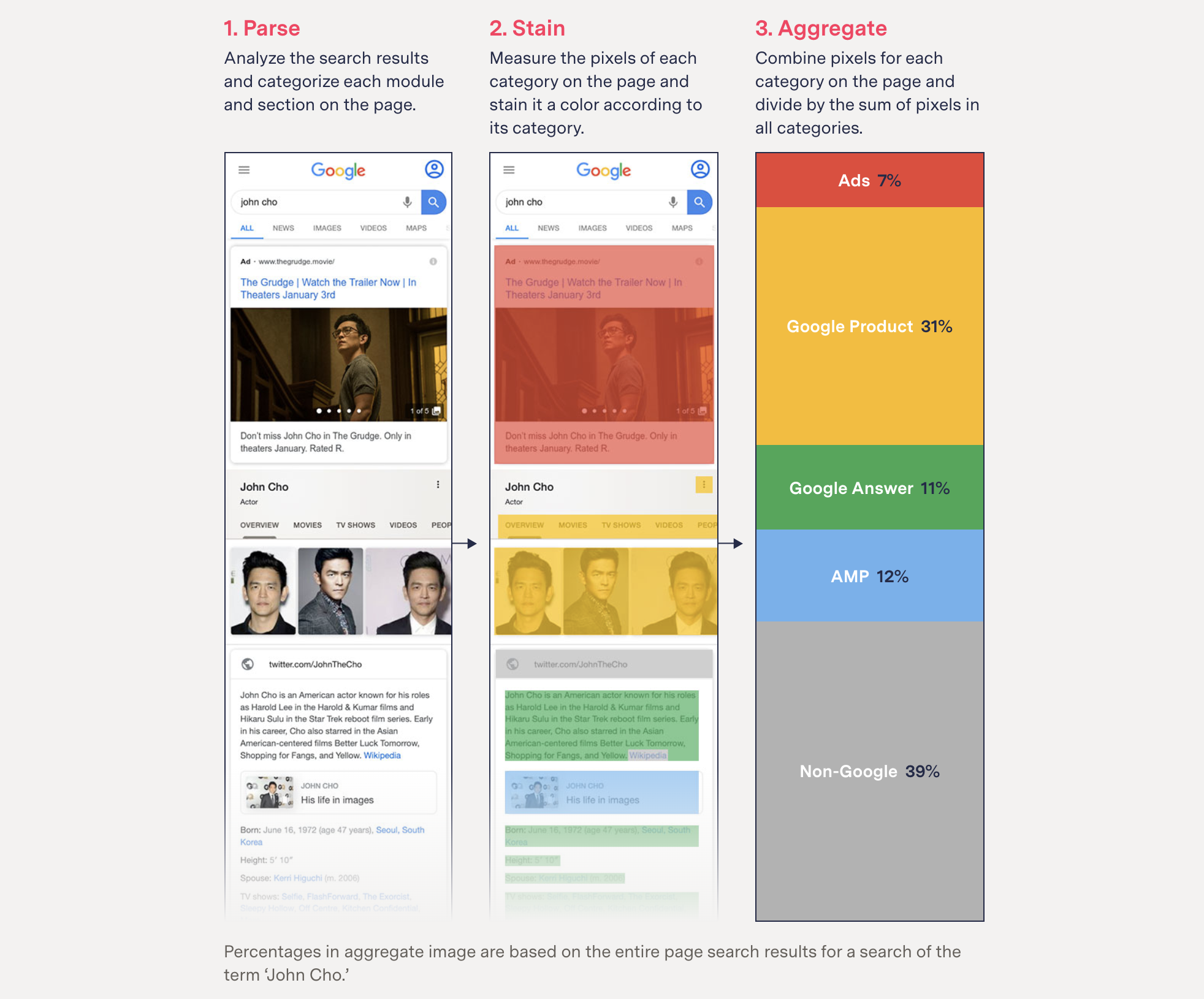
But she had this greater kind of moonshot story of being like, how much of Google is Google? And so we start talking about that and it's like actually rather theoretical to think like what is Google and how do we measure it? And so in this process, we kind of develop this hypothesis-driven checklist of how we approach investigations. So first and foremost, what's the question? What's the hypothesis? How much of Google is Google? And then the question is like, how are we going to test that? How are we going to build the dataset?
So, you know, luckily Google is really easy to scrape. So we scraped the most popular searches from, I think, Google Trends. We did that for a few months, got a few thousand popular searches all on an Android or an iPhone X that we emulated using Selenium, which is a browser automation tool usually used to test websites. We used it to collect websites, and then we spent months trying to figure out what Google was. So we looked through source code, we talked to a bunch of sources in SEO to figure out what it was.
Then we've developed this very naive system where first we’re like, well, if it's Google.com or YouTube, it's probably Google, right? But it got more sophisticated, kept building and building. And so we also developed this way of actually staining the web page and getting the real estate because even though we could tell it was Google, we still need to measure something, right?
And so we ended up finding this way to selectively create bounding boxes around different elements of the page, some that were Google and some linked out and we colored a specific color, then took the sum of that color divided by the total real estate of the page and it ended up being something like 42% of the first page was all to Google.
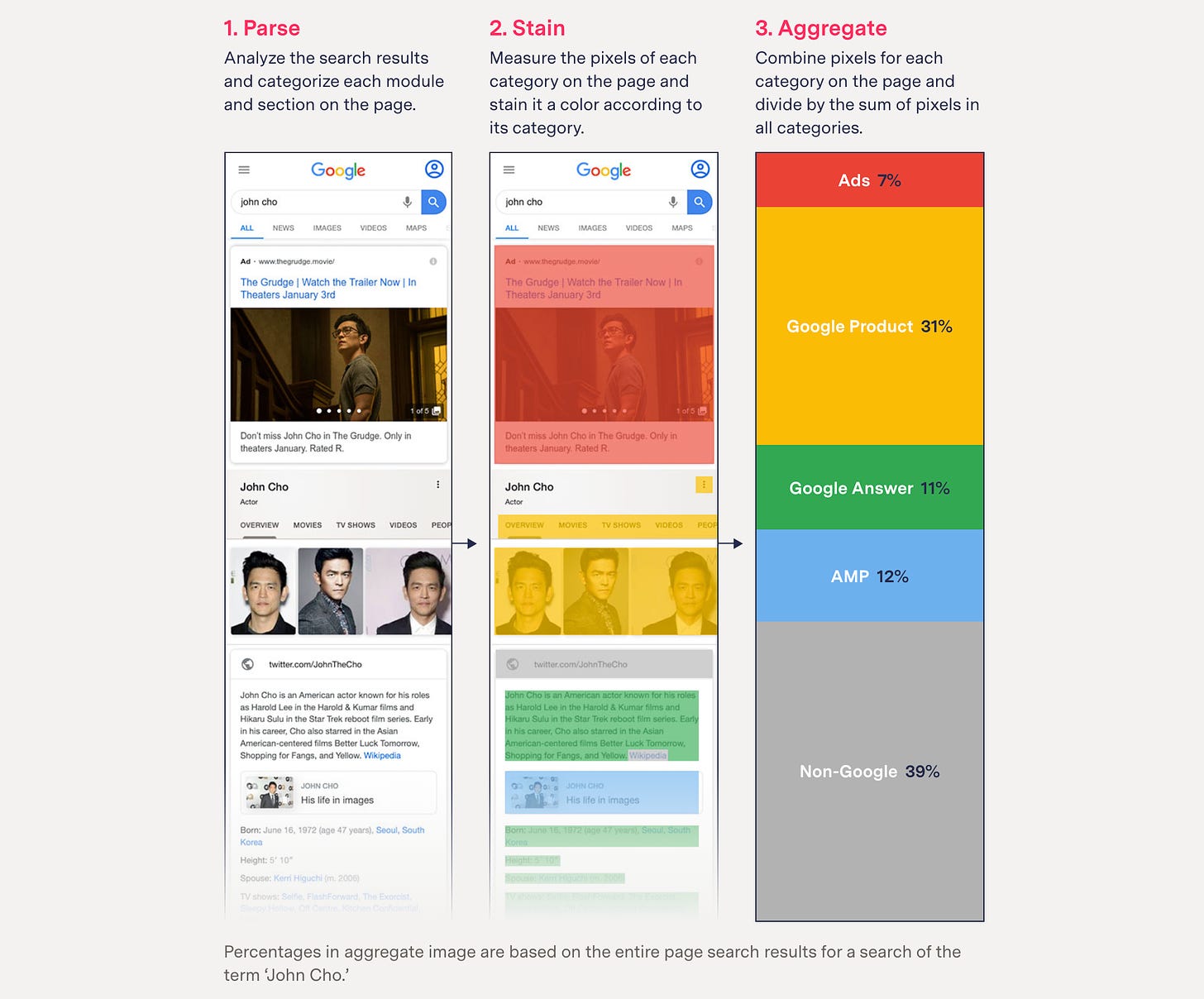
And so that was like a stat that we finally had about this kind of theoretical stat that everyone kind of knows. It's like, yeah, Google self-preferences itself, it owns the bakery, it makes the bread, like of course it's going to be like, “check out our rolls,” right? But to actually find that number was really powerful. And so, I love doing that thing where there's like common knowledge but no evidence, right?
So we go in and fill that void. And so when that came out, there was also the congressional hearing about antitrust, where all of the big tech CEOs were being questioned by Congress and in the opening remarks, I think David Cicilline, brought up our work when they're questioning Google. And it was just unbelievable. We're like, my God, how’d this happen? So sometimes our work has this impact and we have no idea it's going to happen or timing happens quite well. I don't know if we went to his staff and like, shared those documents. I don't know if we always do that. I don’t think we did in that case.
A very similar thing happened with our investigation of Amazon, which was a logical follow-up. How can we do this from another big tech platform that self-preferences itself?
So we looked at Amazon private label products, popular Amazon searches, and within days of publication, which is like pretty much a year later — these investigations take like about a year — a year later, they sent a letter to Amazon leadership being like, under oath you said that Amazon doesn't preference its products, but this study says directly the opposite of that. Please explain.
And so it's just amazing. When we pitch stories, we always think about that accountability angle. Like, what is the thing that's being broken? Who's being impacted?
Like they lied under oath and we can prove that. Or a law is being broken. So I feel like that's the way we frame our stories. Often it just so happens that that happened to be something that an executive said under oath.
We didn't even know that at the time, but it happened. And so, yeah, that's some of the impact we've had.
In Old News: How do you figure out if a resource-intensive story is viable?
Leon: One thing that helps me determine — me and my editor — if the story’s viable is this kind of checklist I mentioned before. And so one of the questions off the bat is can you test something with data? How would you get the data, how difficult it's going to be? What do you have to classify, categorize? We always end up with having to ascribe a value to data because oftentimes the output variable that we're looking for— like what's Google, what's Amazon — it's not a neat column. And so we have to figure out what it is. And so not only do we have to figure out what it is, we have to figure out what that dataset is, what that universe is like. Where do you stop, right? What's enough? What's a quick test to see if something's viable?
And so I approach it as such. Where like, I'm always thinking about these questions and trying to fill them out and approach my editor with as many as possible before we go fully in.
And another thing that we do, as I mentioned, is we do a quick test. So it's like, what's the minimum viable analysis to prove that something is measurable, something's afoot? Like if a pattern is available.
That's actually how my most recent story on internet disparities in the United States started, which we were trying to reproduce an academic article. And so they looked at a ton of different internet service providers in nine states. And originally I was tasked to just reproduce it. And so to do that, I was like, well, let's do one provider, one small city, let's see what we find. And what I found was that every internet speed, first of all, there are pockets of where fast speed were and where slow speed was. Which seemed kind of unfair, but also the prices were exactly the same despite if you're getting fast speeds or slow speeds. And we joined census data and found that it was really skewed. Like lower-income people were getting more slow speeds at the same price.
And so that quick test not only tells you the viability but whether you have a different story. And so we changed our story angle from being that like academic study, which is more of a policy story to a consumer side story of being like you're getting a bad deal and it's happening all across the country, right? So that's another way.
So within this checklist of questions that we ask, we also think about things like, what's a quick analysis you can do to show there's something. That’s something I send my editor and then we discuss. And so it's usually clear if you have a story or not. It's really clear if you have a better story or not. And it's also clear if you need to kill a story, right? If you have just unanswerable questions of things that are just too uncertain.
In Old News: How important is it for journalists to show their work?
Leon: I think the reason why Julia Angwin had emphasized the necessity to do that is to build trust, right? To say that like we're not p-hacking, we're not making shit up. This is the evidence. And you can see exactly how we got to our conclusions. You can draw your own conclusions, right?
And so I think there's a lot of strength in that. And I just keep going back to just traditional journalism. It's like if you have documents or interviews, you would host somewhere like Muck Rock or on DocumentCloud, right? To be like, here's my FOIA [Freedom of Information Act] request. Here is the information that I got from that request.
Fundamentally, it's similar [to my work] where it's like I'm making a request not to a government agency but to a website. Here's what I ask them for. Here's the document that they gave me and here's what I did with that document. So I just see building on traditional journalism. Just at a scale and using a different kind of language of doing so.
But I think it all kind of goes back to the fundamentals, like all good things. I think that I would love to see more newsrooms invest in this evidence creation of like building their own data sets to answer questions. I have seen longer write-ups and methodologies become more popular. Consumer Reports, their investigative team does that. The Washington Post does that. So I'm starting to see more of a change, but it's still a rarity, right? Whereas like most of the stories I work on, it's a necessity, right? Because we just want me, my reporter, my editor and whoever we investigate all have to understand that we have the information down. And that we all know exactly what's being measured, where it comes from, our assumptions, the limitations.
It's all emphatic and necessary to make bold claims that are accurate rather than making bold claims that are actually unsubstantiated by evidence, [where] it's not clear how you got it. It's not clear what test you ran. So like, I think it's all about the details, but making them really apparent, right? Of everything important to it to be like, this is solid. And we did nothing, nothing to exaggerate what you're seeing. The clearest examples of disparities, of patterns, are so apparent. And I feel like it's our job just to be like, look, if you just look, you just put the data together, follow the pattern, anyone will find the same conclusion. Right?
And so I think that that's really the emphasis for me is I just really want to emphasize how we build that dataset, right? And that's like a skill that I'm hoping to impart on others.
I have a tutorial for a skill that I use a lot, which is finding undocumented APIs. So like, you know, APIs are like how servers interact with the website and there are a lot of them that aren't official APIs, but they still work on websites. It's like a subset of web scraping. And like almost every story I work on is thanks to finding one of those. To me, data is just another thing you have to fact-check, right? But not anyone is capable of doing that. And so you're kind of largely responsible for it. That's why I feel like that review stuff is super important just to make sure that everything is accurate, reproducible, explainable, and oftentimes, too, I'll try something several different ways, right? And hopefully those ways all land on the same answer. It assures you’re not cherry-picking and it assures that you've chosen a method that's reasonable, right? Because we have these long methodologies, we can disclose that. To be like, we tried another categorization scheme or we tried another model and the results are interpreted very similarly. So, you know, because data is made public like others could do that too, right? So that's a great strength of our work.
It's like, well, if you want to try it, you can like, it's right here, you can compare it to this.
In Old News: How did you get to where you are today — an investigative data journalist?
Leon: I graduated from NYU with a degree in chemistry. I was working a lot in biogeochemistry, so that's a lot of oceanography. I was doing computational kind of oceanography. And right after I graduated, I got an internship at NASA and there I was learning a lot of what later became like data science tools. At the time I didn't know what the term was. I was mostly recruited to work there to work on a database of synthesizing data from a bunch of studies on seawater chemistry and writing a Fortran model to process it because they use Fortran at NASA. And that's when I started learning about data science. But then I decided not to get an advanced degree in ocean sciences, and I wanted to pursue data science more. So I worked at Sony as a junior data scientist for a while. I built a lot of data pipelines. I learned about ETLs, databases, I learned about machine learning for the first time and implemented one on the job.
And at the time I started getting interested more in how to use these tools for more impactful work. So I saw a role open up at NYU. It was called SMaP at the time, but now it's called CSMaP for the Center for Social Media and Politics. It’s kind of the interface of data science applied to social science problems.
So I worked there as a research scientist/engineer for a while, building a lot of open-source tools, learning a lot about social science. How to design an experiment. And during that time I got introduced to social media platforms because I had built a lot of data pipelines and publications there that were working, doing research, doing that. But there are a lot of questions that were left unanswered, a lot of platforms that went un-studied. Like I was really interested in YouTube that whole time and there just wasn't a great answer for that. And so during that time too, Julia Angwin’s machine bias work came out, seminal work about recidivism algorithms. I saw her talk about it at some conference and was like, “What is this? Like? This is journalism? Like, journalism can be so impactful, data-oriented, so thorough?”
She founded The Markup shortly thereafter or, like a few years after that, actually. And so, you know, I heard her pitch for it of being like, we're going to build our own datasets to hold tech accountable. I found that it would be a great outlet to pursue a lot of questions I had. And look at the platforms that were being un-looked at in my academic position and I had the skills through all those different practices of like building data pipelines, learning how to run experiments. So this was kind of a natural fit. It was unbelievable that a place opened up where all those skills can come together.
And so I interviewed and I met Julia and we kicked it off. It's actually funny because I was being interviewed as a source for another story, and other sources kept routing them to me. And so I talked to Aaron Sankin, who's my current colleague as a source, and he was like, I think we're interviewing you too. And I was like, ‘Yeah.’ So it's kind of funny because at the time I was working a lot on like memes and, you know, image campaigns and I was like, they're working on hate speech at The Markup or something that they never published. But we kind of crossed there.
And so, yeah, I started at The Markup originally as a data science editor because they want to use my expertise to like up our data science capacity in the newsroom. But it felt weird having a role of editor when I hadn't worked on stories before. As you can imagine, it's like, where does authority come from? Authority comes from experience.
I had no experience of writing stories. However, I started working on some stories, I really loved it. And at some point me and Julia Angwin were just like, you know, maybe I should just become a data journalist and just focus on stories and just make that my main priority.
And that's what I did and I haven't looked back. It's been absolutely wonderful to work on these stories, like really kind of engraving them, like how we do ‘Show Your Works,’ which is our methodology. That played a really heavy role doing that, having authored so many of them. And it's been really great.
So, you know, maybe I'll become an editor one day, but right now I'm having a really good time just working on stories.